はじめに
コンピュータの高速化・高機能化のために CPU(プロセッサ) は進化を続けています。
初期において CPU の高速化は "CPUのビット数を上げる" ことと, "クロックを早く" することでした。
その後 キャッシュメモリの搭載, パイプライン処理, スーパスカラ処理, RISCとCISCとの競合, マルチコアプロセッサ化 などが行われてきました。
今回は どうようして CPU の高速化が図られたきたか 具体的なことについて説明していきます。
CPUのビット数を上げる
まず CPU のビット数を上げて 一度に処理できるデータ量のビット数を上げることです。
8ビットCPU が16ビットの演算をすると2回の演算処理をしますが, 16ビットCPUなら1回の演算処理ですみます。
1970年代の初めの 4ビットCPU からスタートし, 8→16→32CPU の順に, 2000年代の初めには 64ビットCPU が登場しました。
高クロック化
CPUの高クロック化とは、クロック周波数が高いほど、同じ処理をより短時間で完了でき、パフォーマンスが向上します。
例として「4bit時代で 500KHz, 8bit時代で5MHz, \(\cdots\)64bit時代で 3GHz」と上がってきました。
単純比較で4bit時代とは60万倍クロックが上がっています。
しかし, クロックを上げると, CPU の発熱が上がり そのため強制冷却を行いなす, またクロックを上げるとさらに発熱が上がり, 冷却を強化します, …いたちごっこでした。
2000年代の初め頃, 高クロック化は 4GHz程度に収まり, これが
限界との様子を呈しました。
☞高クロックによる高速化【参照先】
☞高クロックの問題の詳細(閑話に後述)【参照先】
ブーストクロック
一般にPC(パソコン)はCPUのスペックの最大周波数より十分低いクロックで動作しています。
CPUが十分に冷却されて、動作温度に余裕がある時に有効にし, GPU(グラフィックコ・プロセッサ)を含めたCPU のクロックを上げて,画像処理などの処理速度を上げ, システム全体のパフォーマンスが向上させます。
この周波数(最大値)のことをブーストクロックといいます。
また 処理速度を上げるため, 単にクロックを上げることをオーバクロックとは言います。
単に オーバクロックするときは 温度上昇に伴うCPU などの寿命低下対策のため 冷却の強化が必要になります。
インテルでは"インテル® ターボ・ブースト・テクノロジー" が 安全管理のもとで, クロックを上げて処理速度を高める技術があります。
発熱量に応じてCPUのクロックを変動する技術で, そのときの動作環境によって高速に動作させることが可能です。
キャッシュメモリを内臓
高速であるCPU では アクセスするメインメモリやストレージの応答が遅く, 待ちが生じます。
そこで読み書きが高速なSRAM
(スタティックRAM)の 「
キャッシュメモリ」 を搭載し, よく使うプログラムやデータをあらかじめこのキャッシュメモリへ格納して, 応答遅延を改善しています。
CPUに近いものから、1次キャッシュ(L1)、2次キャッシュ(L2)、3次キャッシュ(L3)と呼ばれています。
またシステム的にキャッシュを より 有効的に使い, CPU全体を高速にする方法
(※)が考えられています。
※:例/
スマートキャッシュ(Intel社)
CPUのキャッシュはコアごとに一定容量を割り当てていますが、コアが要求するキャッシュ容量を、全体のキャッシュの中からフレキシブルに割り当てることができる技術です。多くの容量を必要とするコアがあれば、そのコアに多くのキャッシュを割り当てて, PC を高速に動作させる。
☞メモリの詳細【参照先】
パイプライン処理
以下は命令実行の各ステージ(工程)です。
♦F:命令の読込み(Fetch)
♦D:命令の解釈(Decode)
♦E:命令の実行(Execut)
♦S:結果の保存(Store)
下図は逐次処理,
パイプライン,
スーパーパイプライン,
スーパースカラ の順に記載しています。
逐次処理では F→D→E→S の全ステージを終了してから次の命令処理を開始します。
パイプラインでは命令1のF (ステージ) が終わりD が始まると同時に 命令2のF を行います。
ステージ2以降では複数の命令が同時進行します…このように効率よく実行していきます。
下図において, 逐次処理で命令2 が終るまで, パイプラインでは命令5 が終了できます。
パイプラインをさらに進めたのがスーパーパイプライン です。
また複数のパイプラインを同時に平行に動作(パイプラインを2回路持ったイメージ)させるのがスーパースカラ(スーパースケーラ)です。
各種パイプライン
|
上図のように, スーパーパイプラインは1つのステージを2つに分けて処理します, パイプラインで4つ命令に対しスーパーパイプラインでは7つ命令が終了できます。
さらにスーパースカラでは命令を実行する回路が2つあり, スーパーパイプラインで7つの命令に対し スーパースカラ では8つ命令が終了できます。
パイプラインが 同時・先行処理することにより問題が生じます, この問題をハザードと呼びます。
これらは対策されていますが、その分遅れが生じます。
そしてハザードは次の様に分類されいます。
構造ハザード
同じタイミングで同じハードウェア資源(例えば同じレジスタ)にアクセスするときなどの異常処理。
データハザード
ある命令が直前の命令の処理結果を用いるとき、パイプラインはその結果を待つ必要が生じます。
制御ハザード
分岐命令のとき,結果によって 次の命令が わからず, パイプラインを止めておく必要がある。
こうような時, 結果を予測(分岐予測という)し, 命令をあらかじめ実行してまう方法があります。
予測が外れた場合は分岐命令の直後からの命令をやり直す必要が生じます。
CISCとRISC
•CISC:Complex Instruction Set Computer
•RISC:Reduced Instruction Set Computer
CISC と RISC は、
命令セットアーキテクチャ(※)の設計手法です。
(※):以下の用語説明を参照
CISC
1つの命令が複雑で高度な機能の処理ができ, 様々な処理を少ない命令で実行できるようにして効率を上げています。
パイプラインを取り入れるのは不向きです。
CISC の代表的なCPU は Intelのx86系やx86-64系などです。
・x86系とはIntel社のXXX86となるCPUで,8086,80286,80386など。
・x86-64系とはAMD社のx86系(32bit)に命令互換があり,かつ64bit 命令が実行可能CPUである AMD64, Intel 64など。
1つの命令が 単純な処理しかできないが, 高速な処理ができ,パイプラインを取り入れることができ, 全体の効率を上げることができます。
RISC の代表的なCPU はマイクロシステムのSPARC、IBM/モトローラのPowerPCなどです。
RISC とCISC の論争
さて, CISC は初期のCPUに使われ, RISC は1970年代後半に登場し 使われてきました。
そして, RISC とCISC の論争は ほぼ1980年代~2000年の間に行われました。
CISC の1命令に対し, RISC では複数命令になるが その命令はシンプルで実行時間が短い。
さらに RISC CPU は簡単な構造であり, 高いクロック(周波数)で 動作でき, CISCより安い制作コストですみます。
1990年代にはCISCが優勢(intelが多く採用)でしたが, 実際は CISC のCPU は内部的にRISC技術を採用、RISC のCPU も 内部でCISC技術が使われきました。(両者勇み分けに淘汰した様子ですね!)
その結果2000年代にはCPU のハードの性能が向上し, RISCとCISCの差/境界はほとんどなくなっているようです。
ここで初めての用語または関連した用語を簡単に説明します。
用語の説明
以下の 命令セットアーキテクチャとマイクロアーキテクチャは, 共にコンピュータ設計の一部です。
ISA(命令セットアーキテクチャ)(instruction set architecture)
CPU を動作させる命令語の体系。CPUが 解釈して実行できる機械語(マシン語)の仕様を定めたもの, または命令の集合を命令セットともいう。
マイクロアーキテクチャ(microarchitecture)
CPU 内部の回路の設計や構造のこと。(ハードウェア)
マイクロアーキテクチャと命令セットアーキテクチャは共にコンピュータ設計の一部である。
アーキテクチャ(architecture)
コンピュータやソフトウェア、システム、あるいはそれらの構成要素などにおける、基本設計や共通仕様、設計思想などを指すことが多い。
マイクロプログラム(microprogram)
大雑把にいえば,より複雑な演算を小さい演算に分解し,それぞれをハードで実行する方式です。
(CPU の実行プログラムは機械語の命令群です。)
CISC方式のCPUでは複雑な命令があり、すべての命令に一対一に対応する回路を実現するには不利です。
このとき,1つの命令に対し, いくつかの より単純/簡単なマイクロプログラム(マイクロコード)に分解し,実現できる回路で実行します。
CISC CPUで用いられています。
ワイヤードロジック(wired logic)
論理回路の構成方法の一つで、ハードウェアによる物理的な結線で命令を実行するもの。
すなわち, CPUに各命令に対応する回路群を組込み, 命令実行をするもので, 単純な命令に絞り込んだ RISC CPUで用いられています。
ハイエンド(High end)ミドルエンド,ローエンド
ハイエンドとはPCなどの一連のシリーズの中で最も機能や性能、品質に優れまた高価格なものいう。
ローエンドとは上記内容が最も低いもの。またミドルエンドとはハイエンドとローエンドの中間のもの。
マルチコア化とスレッド
1個のCPU に2個以上のCPUコアを搭載したプロセッサ(CPU) です。
…2コアなら2個のCPU が同時に動いているイメージです…
クロック周波数を上げることが限界に達し, 次の性能向上の切り札が, マルチコア化です。1チップのCPUの中に複数個のCPUコア を内蔵したCPU です。
さらにCPU に負担の小さい命令のとき, 能力に余裕があり、同時に複数の命令を実行できようにします。
この同時に処理できる命令数を"
スレッド数"とよび,
同時に処理できる命令の最大数" を表します。
2000年代から2024年の現在, 一つのCPU に複数のコア数 とスレッド数 を搭載したマルチコアプロセッサー が登場しました。(かってのCPU は 1コア/1スレッド です。)
コア数とは CPU に内蔵しているCPUコアの数, これを物理コア数 といい、スレッド数は 論理コア数といいます。
例えば: 4コア/8スレッドとすると, 同時に処理できる命令数は4, 余裕があると1つのコアで2つまで、最大で8つの命令を同時に処理することができます。
複数の命令を同時に実行してCPU の高速化・高性能化を図っています。
コ・プロセッサ
CPU に内蔵
(または外部直結)し, CPU を補助する 特定の処理装置を
コ・プロセッサ(co-processor)といい, CPU の処理速度は早くなります。
言い方は2通りあります。
•コ・プロセッサ=コプロセッサ
•co-processor=coprocessor
以下は代表的なコ・プロセッサです:
1)GPU /画像処理ユニット
2)FPU /浮動小数点演算処理ユニット
3)NPU /AIプロセッサユニット
(GPU:graphics processing unit)
(FPU:floating-point processing unit)
(NPU:neural network processing unit)
1)GPU は画像処理専用の機能をもち, 3Dグラフィックスを描画するパソコンやゲーム機に使われています。
2)FPUは科学技術計算をはじめ多くの数値計算を必要とするグラフィックス処理などにも使われます。
スーパコンピュータをはじめ 多くの数値計算を必要とする業務のサーバ, ワークステーションなどのコンピュータに使われています。
3)NPUは AI(人工知能)に特化したプロセッサです。
NPUはニューラルネットワーク(※1)の処理を効率化できるハードウエアです。
機械学習やディープラーニングなどのAI処理が高速化されます。
現在(2025年1月), 世界的に注目され 急成長している技術で 各社が力を入れ開発しています。
※1:ニューラルネットワークとは AI技術において, 人間の脳の神経細胞(ニューロン) の信号のやり取りする仕組み/働きを模倣した計算モデル(※2)のこと。それを多層構造にしたシステムをディープラーニングです。
※2:数学的に表現し真似た機械学習モデル
…以上
興味のある方へ
高クロック化の問題点
高クロック化による CPUの発熱の主な要因は以下によります。
微細化技術が進み, 集積度が高まり, CPU に搭載の
トランジスタ数は1971年のintel 4004では
2300個, 2000年のPentium4では
4200万個(42,000,000)となっています。
そして「クロックが上り, 同時に作動する
トランジスタ数が増加すること」により発熱が大きくなります。
CPU の性能向上(高集積度)と高クロック化による発熱に対し, CPU を直接冷却する 空冷CPU, そして究極の水冷CPUも登場しました。
(一般に半導体の耐熱温度は125℃程度です。)
また半導体の微細化とクロックの高周波によるリーク電流の発生の問題も生じました。
(※)
注(※):CPU の微細化により信号線間の距離が微小であることと, クロックの高周波,トランジスターのスイッチングの高頻度(高周波化)などの誘導によるリーク電流が発生と思われる。
以上よりクロックを上げることには限界があり, マルチコア化にむけて高速化・性能アップが進められてきました。
クロックの波形
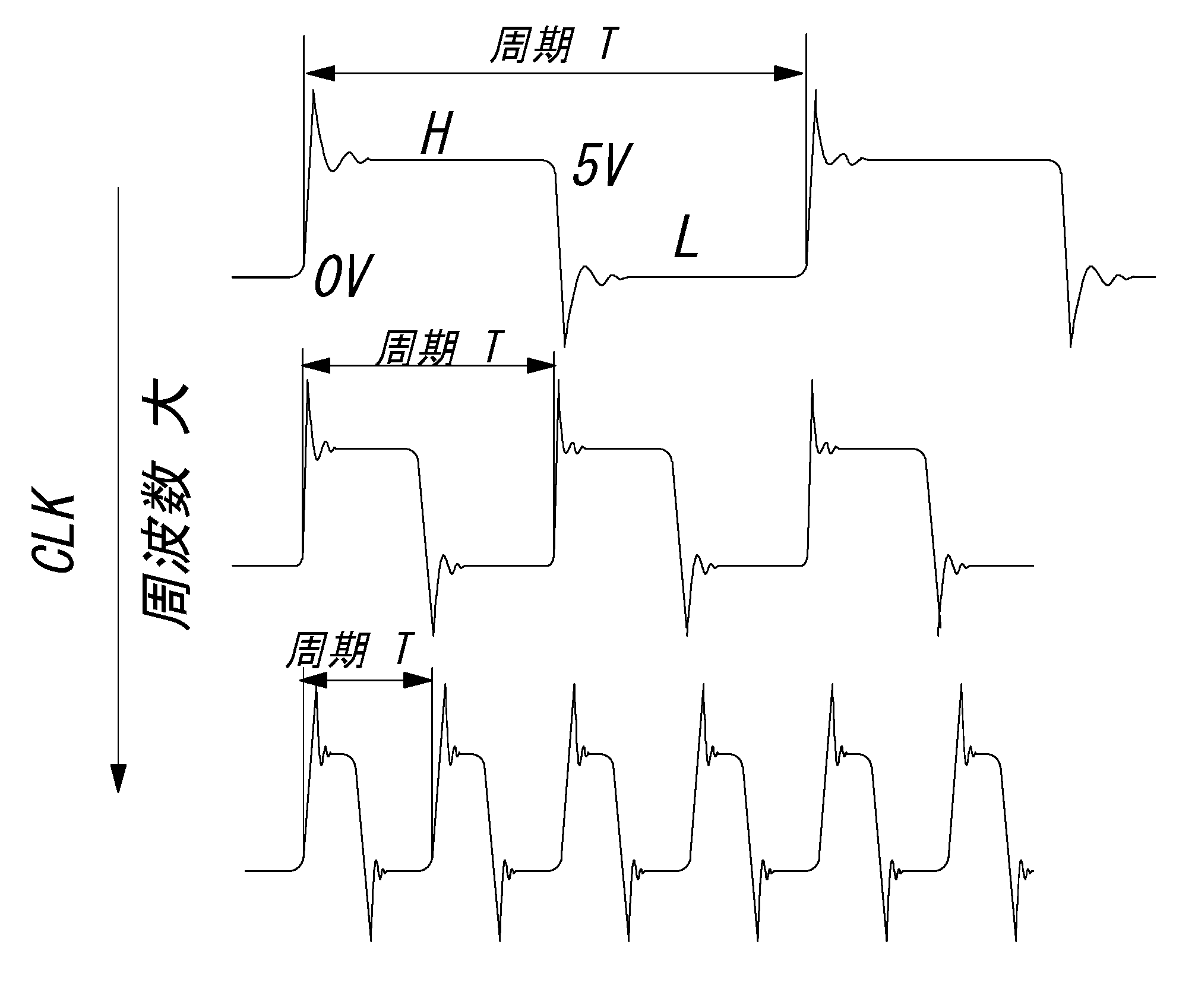
fig2 クロック波形
周波数が高くなるにつれて 本来の矩形波 が 変形(立ち上がり・立下りの鈍り,時間遅れ発生)し, 矩形波からかけ離れた三角波のようになることもあります。
(上図は反射の影響は考慮していません)
立ち上がり・立下り時のひげ状の波形(過渡現象の影響による)は修正可能ですが, そのかわり波形の鈍りが大きくなることがあります。
(上図は実測定のものではありません, 机上で想定したものです。)

